

Hey, guys!. When it came to finding a topic for my first blog post, I first thought of another topic… but then I remembered my student research project and thought it was actually fun! The student research project was about NLP (Natural language Processing), maybe I’ll tell you more about it in another blog post.
Almost as interesting as NLP is our Telegram group! Since last week we have our own stickers (based on photos of us). Well, this escalated quickly 😛 This kind of communication is interesting and I wonder if my basic knowledge of NLP is enough to get some interesting insights from our group conversations?…
That’s exactly what we’re about to find out! In this blog post, we will extract a telegram chat, create a domain-specific Word2Vec model and analyze it! You can follow me step by step!
But before we start, we should think about how we want to achieve our goal. Our goal is to find some interesting insights from a chat group without any mathematical shenanigans. To achieve our goal we have to do three things:
- Convert a telegram chat to a format suitable for the computer,
- train an own Word2Vec model based on the data set obtained in the first step and
- use the Word2Vec model to find insights.
Exporting A Telegram Chat
That’s the easy part! First, we need a Unix/Linux system because we will use the Telegram messenger CLI for extracting the chat. I personally use a Windows 10 installation, so I installed an OpenSUSE WSL (Windows Subsystem for Linux) from the store. Once OpenSUSE is installed, we start OpenSUSE and clone the repo:
git clone --recursive https://github.com/vysheng/tg.git && cd tg
As you can see from the README of the project, we need additional libraries to build the project. That’s why we simply install all dependencies:
sudo zypper in lua-devel libconfig-devel readline-devel libevent-devel libjansson-devel python-devel libopenssl-devel
Then we can build the project:
./configure
make
Good job! We have already come quite a bit closer to our goal! Now we still have to
Install gram-history-dump. This is best done in another window so that we can run Telegram messenger CLI! Once you have installed telegram-history-dump you start the Telegram messenger CLI and follow these instructions:
telegram-cli --json -P 9009
Now we can execute the telegram-history-dump to get a JSON from our chats (ensure the Telegram messenger CLI is running):
ruby telegram-history-dump.rb
Very good. Our telegram chats are now saved as .jsonl. Personally, I prefer to work with .csv files. Therefore I adapted a small script which converts the .jsonl into a .csv file. You can download the script from our GitHub Repo and use it as follows:
python3 jsonl2csv.py <your>.jsonl chat.csv
Finished! Now we have gained a small dataset from Telegram. Time for the next step!
Train an own Word2Vec model
Word2Vec is an unsupervised machine learning algorithm developed by a team of researchers led by Tomas Mikolov at Google, which contains a word as input and returns a vector representation of this word as output. Other than a simple WordCount vector, a Word2Vec vector contains semantic characteristics of the word. The special thing about Word2Vec is that it is able to learn this representation completely unsupervised, all the algorithm needs is a corpus, which is the whole lexicon, on which it is trained. Word2Vec then tries to learn the meaning of a word based on the words that appear near that word. The construction of a vector based on Word2Vec can also be imagined as a weighting of dimensions of different meanings.
However, I will not go into the exact functionality of Word2Vec now, because that could fill an own blog post! But I think that I will soon write a blog post about it. Subscribe to our blog! Today we will only look at how we can create our own Word2Vec model with the help of gensim and then investigate it a little bit. For this, we will also apply typical steps of data preprocessing of NLP tasks. I will try to explain them as briefly as possible. However, I must ask you to read the details somewhere else or otherwise this blog post would be far too long. I prepared this blog post with Kaggle. I recommend using Kaggle if you want to try it yourself. Each code snippet corresponds to a cell in Kaggle.
So let’s start with the annoying part. First, we need to import a number of Python libraries. These include all the functions we need for our task
import pandas as pd
import csv
from nltk.tokenize.casual import TweetTokenizer
import nltk
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
from nltk.corpus import stopwords
Good work… again :). Now we are finally ready and can get to the fun part. First, we have to read our previously created dataset. The perfect data type for this is pandas dataframe, which is considered to be the standard for data science tasks in python. The great thing: we can create a dataframe directly from a CSV file. Additionally, we need a list. In this list, we will store a list with the tokens of each set in our corpus. Simplified we can now think that every word is assigned to a token. For example, the word “hello” is mapped to the hello-token
df = pd.read_csv('../input/chat.csv', delimiter=' ', quotechar='|', quoting=csv.QUOTE_MINIMAL)
sentences = []
Now we have to break down each sentence or more specific each telegram message into tokens and add them to our corpus. Therefore we iterate over our dataframe and get the value in ‘text’. We can ignore the other columns for this example. Now we filter out all messages labeled with ‘no text’. These are mostly gifs we’ve sent.
One problem we have to deal with is the fact that we have a very very small dataset. Therefore we try to keep the variety of possible tokens as small as possible. First of all we remove all stopwords. In the context of NLP, stopwords are words that do not provide a semantic contribution to a statement. For example, articles. Articles are of great importance for grammar, but none for meaning. Word2Vec is an algorithm that maps the semantic meaning of a word into a vector, therefore we can remove the stopwords. To generate the tokens we use a ready-made Tokenizer from the NLTK package. This is specially designed to create tokens from tweets. Since tweets are probably very similar to chat messages, we use them to generate tokens.
deu_stops = stopwords.words('german')
sno = nltk.stem.SnowballStemmer('german')
for index, row in df.iterrows():
text = row['text']
if not text == 'no text':
tokens = TweetTokenizer(preserve_case=True).tokenize(text)
tokens_without_stopwords = [sno.stem(x) for x in tokens if x not in deu_stops]
corpus.append(tokens_without_stopwords)
I’m afraid I must show you some magic now. The following lines define some parameters, which are needed for the training of our Word2Vec model. But since I haven’t explained the functionality of Word2Vec in detail in this blog post, it doesn’t make sense to explain these parameters now, see them as God-given 🙂
num_features = 300
min_word_count = 3
num_workers = 2
window_size = 1
subsampling = 1e-3
Ready! Okay, maybe not yet, but now we can generate our Word2Vec model with a single line of code:
model = Word2Vec(
corpus,
workers=num_workers,
size=num_features,
min_count=min_word_count,
window=window_size,
sample=subsampling)
Done! We have created our own Word2Vec model. Nice! So better save it quickly:
model.init_sims(replace=True)
model_name = "billigeplaetze_specific_word2vec_model"
model.save(model_name)
Finding insights
So finally it is time… We can look for interesting facts. The first thing we want to find out is how broad is our vocabulary? Allegedly the vocabulary correlates with the education so how educated are the Billige Plätze? I suspect nothing good :O.
Attentive readers will ask themselves why we first created a Word2Vec model to determine the vocabulary. Yes, we could have used the number of unique tokens earlier, but what interests us more is how many words our Word2Vec model contains. This will be less than the number of tokens, as many messages are too small to be used for training and words can get lost.
len(model.wv.vocab)
>>> 3517
Fascinating! The Word2Vec model we created based on the group chat of Billige Plätze uses only 3517 words. Attention, emojis also fall in here!
Now we are also able to answer the important questions in life! Who’s more of a Dude, Leon or me? What do you think? Ah, no matter we can use our Word2Vec model!
print(model.wv.distance('leon','dude'))
print(model.wv.distance('cem','dude'))
>>> 0.00175533877401
>>> 0.000874914626021
I always knew 🙂 Nice. But we can do more. In the Billige Plätze group, we often use the word ‘penis’ but with which other words is the word ‘penis’ associated? Let’s ask our word2Vec Model!
model.wv.most_similar('penis')
>>> [('gleich', 0.996833324432373),
('Marc', 0.9967494010925293),
('abend', 0.9967489242553711),
('hast', 0.9967312812805176),
('gemacht', 0.9967218637466431),
('gerade', 0.996717631816864),
('kannst', 0.9967092275619507),
('Ja', 0.9967082142829895),
(':P', 0.9967063069343567),
('?', 0.9967035055160522)]
We are even able to visualize our Word2Vec model to make the “core language” visible! We use t-SNE for dimensionality reduction to get two-dimensional vectors that we can then visualize in a scatter plot. With sklearn, the code is very manageable!
vocab = list(model.wv.vocab)
X = model[vocab]
tsne = TSNE(n_components=2)
X_tsne = tsne.fit_transform(X)
df = pd.DataFrame(X_tsne, index=vocab, columns=['x', 'y']).sample(1000)
and now we can plot it with ploty
plt.rcParams["figure.figsize"] = (20,20)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df['x'], df['y'])
for word, pos in df.iterrows():
ax.annotate(word, pos)
We can see very clearly how certain words gather and others are very far away. So you can see which words are related to each other and which are not.
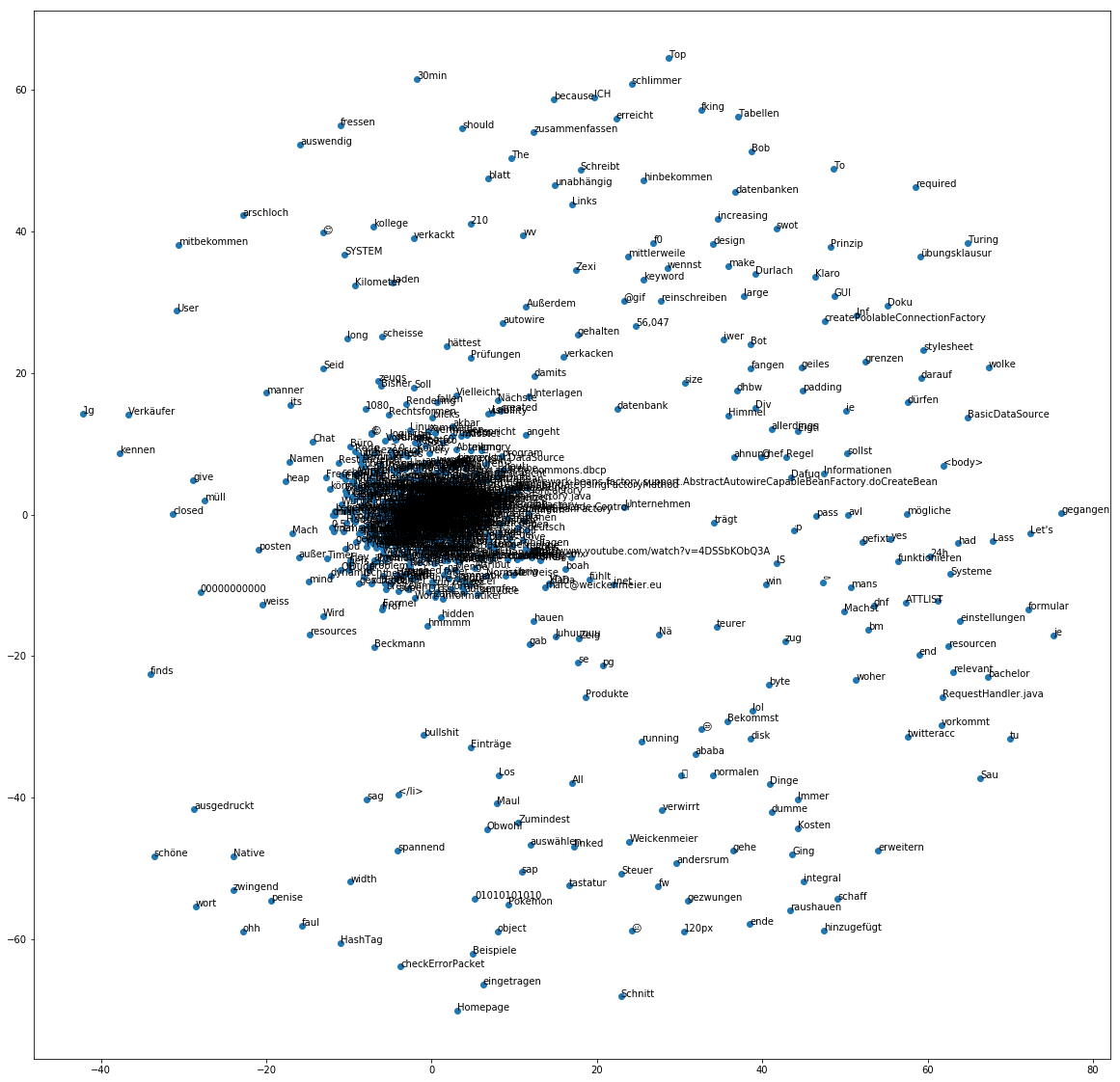
The End
So people, let’s recap what we’ve done: First we used the WSL (Windows Subsystem for Linux) to run a Linux program to export our telegram chats! We then used the NLTK (Natural Langue Toolkit) to convert the exported chat messages into tokens. With the help of gensim we trained our own Word2Vec model based on these tokens. Finally, we used Ploty and Sklearn to visualize our model!
I hope you guys enjoyed it as much as I did! See you soon on our blog again!