

These days is Interspeech conference 2018 where I’m invited as a speaker and as they write on their website…
Interspeech is the world’s largest and most comprehensive conference on the science and technology of spoken language processing.
Coming Wednesday the results and systems of 2nd Spoken CALL Shared Task (ST2) are presented and discussed in a special session of the conference. Chances are that these discussions will lead to a third edition of the shared task.
With this blog post, I want to address all newcomers and provide a short comprehensible introduction to the most important challenges you will face if you want to participate at Spoken CALL shared task. If you like “hard fun”, take a look at my research group’s tutorial paper. There will be unexplained technical terms and many abbreviations combined with academical language in a condensed font for you 🙂
What is this all about?
The Spoken CALL Shared Task aims to create an automated prompt-response system for German-speaking children to learn English. The exercise for a student is to translate a request or sentence into English using voice. The automated system should ideally accept a correct response or reject a student response if faulty and offer relevant support or feedback. There are a number of prompts (given as text in German, preceded by a short animated clip in English), namely to make a statement or ask a question regarding a particular item. A baseline system (def) is provided by the website of the project. The final output of the system should be a judgment call as to the correctness of the utterance. A wide range of answers is to be allowed in response, adding to the difficulty of giving automated feedback. Incorrect responses are due to incorrect vocabulary usage, incorrect grammar, or bad pronunciation and quality of the recording.
How to get started
A day may come when you have to dig into papers when you have to understand how others built their systems, but it is not this day. As someone who is new to the field of natural language processing (NLP) you have to understand the basics of machine learning and scientific work first. Here are the things we will cover with this post:
- Machine learning concepts
- Running the baseline system
- Creating your own system
Machine learning concepts
When my research group and I first started to work on the shared task we read the papers and understood barely anything. So, we collected all the technical terms we didn’t understand and created a dictionary with short explanations. Furthermore, we learned different concepts you should take a look at:
Training data usage
For the 2nd edition, there was a corpus (=training data) containing 12,916 data points (in our case speech-utterances), that we can use to create a system. A machine learning algorithm needs training data to extract features from it. These features can be used for classification and the more varying data you have, the better the classification will be.
But you can’t use all that data for training. You have to keep a part of your data points aside so you can validate that your system can classify data it has never seen before. This is called validation set and the other part is called training set. A rookie mistake (which we made) is to use the test set as validation set. The test set is a separate corpus, which you should use at the very end of development only to compare your system with others. For a more detailed explanation take a look at this blog post.
If you don’t have a separate validation set (like in our case) you can use cross-validation instead, which is explained here. Furthermore, you should try to have an equal distribution between correct and incorrect utterances in your sets. If this is not the case, e.g. if you have 75% correct utterances and 25% incorrect utterances in your training set, your system will tend to accept everything during validation.
Metrics
Metrics are used to measure how well a system performs. They are based on the system’s results, which generally displayed as a confusion matrix:
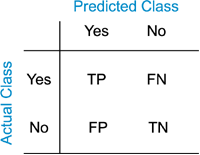
- TP: True positive (a correct utterance has been classified as correct?)
- FP: False positive (a faulty utterance has been classified as correct?)
- TN: True negative (a faulty utterance has been classified as incorrect?)
- FN: False negative (a correct utterance has been classified as incorrect?)
Based on the confusion matrix there are four often used metrics: Accuracy, Precision, Recall and F1. When to use which is explained thoroughly here. For the shared task, there’s a special metric called D-score. It is used to evaluate the system’s performance respecting a bias to penalize different classification mistakes differently. More details about D-score can be found in our tutorial paper.
Running the baseline system
If you open the data download page you can see an important differentiation: On the one hand you can download the speech processing system (also asr system or Kaldi system) and on the other hand you can download the text processing system. Basically, you have to independent baseline systems you can work on.
For the asr system to work you have to install several applications. This is one of the pain points. Be careful here! Kaldi is the speech processing framework our baseline system is built on. The things you need for Kaldi are Python, Tensorflow, CUDA, and cuDNN. The latter two are for Nvidia graphics cards. cuDNN depends on CUDA so check out that the versions you install match. Furthermore, Kaldi and Tensorflow should be able to use the installed Nvidia software versions. To find out if everything went well you can try Kaldi’s yes/no example as described in:
kaldi/egs/yesno/README.mdThe text processing system can be run using just python and is pretty minimal 😉 At least during ST2 it was. You can either check if there’s a new official baseline system for text processing, or you can use one of our CSU-K systems as a basis:
https://github.com/Snow-White-Group/CSU-K-Toolkit
Creating your own system
To create your own system you first have to decide whether you want to start with text- or speech processing. If you are a complete beginner in the field, I would advise you to start which text processing because it is easier. If you want to start with speech processing take a look at Kaldi for dummies, which will teach you the basics.
The Kaldi system takes the training data audio files as input and produces text output which looks like this:
user-008_2014-05-11_17-57-14_utt_015 CAN I PAY BY CREDIT CARD
user-023_2014-11-03_09-47-09_utt_009 I WANT A COFFEE
user-023_2014-11-03_09-47-09_utt_010 I WOULD LIKE A COFFEE
user-023_2014-11-03_09-47-09_utt_011 I WANT THE STEAK The asr output can be used as text processing input. The text processing system produces a classification (language: correct/incorrect, meaning: correct/incorrect) from the given sentence as output.
Now you should be at a point where you understand most of the things described in the papers, except for the concrete used architectures and algorithms. Read through them to collect ideas and dig deeper into the things that seem interesting to you 🙂 Furthermore here are some keywords you should have heard of:
- POS Tagging, dependency parsing
- NER Tagging
- Word2Vec, Doc2Vec
- speech recognition
- information retrieval
I hope you are motivated to participate and if so, see you at the next conference 🙂
Greets,
Domi